
Sorteringsportföljer
En vanlig genväg som kostar mer än den smakar

Inom kvantitativ aktiehandel finns en teknik som används nästan överallt men sällan ifrågasätts.
Man sorterar aktier efter en faktor, köper tex de 20 % bästa och ibland blankar de 20 % sämsta.
Det är enkelt.
Det är intuitivt.
Och det är lätt att förklara.
Men enkelheten döljer flera problem. I praktiken kastar sorteringsportföljer bort mycket av informationen i signalen och skapar onödig omsättning i portföljen. Resultatet är ofta att en stor del av det alfa man tror sig ha hittat försvinner på vägen.
Problemet med sorteringsportföljer
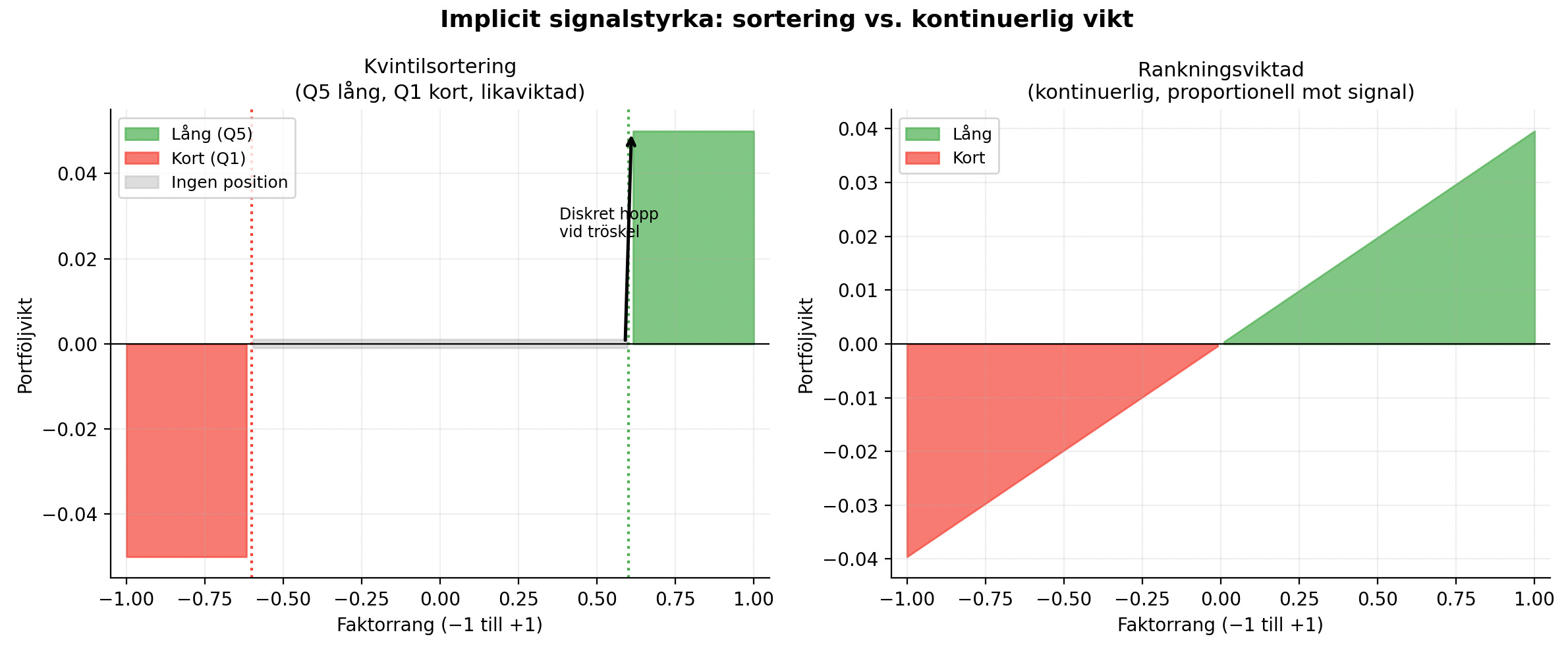
När man delar upp aktier i kvintiler och lika viktar varje grupp ignorerar man i princip all gradientinformation i signalen.
En aktie som rankas etta och en som rankas femtonde i toppkvintilen får exakt samma vikt, trots att skillnaden i förväntad avkastning kan vara stor. Signalens styrka spelar ingen roll. Det enda som betyder något är vilken “hink” aktien hamnar i.
Ännu tydligare blir problemet vid hinkarnas kanter.
En aktie som ena dagen rankas 30:a och nästa dag 31:a kan plötsligt gå från full position till noll i portföljen, trots att den underliggande faktorpoängen knappt har förändrats. Det leder till stora diskreta affärer som inte drivs av ny information utan av en godtycklig gräns.
Många försöker mildra detta genom att införa trösklar innan man handlar. Det kan minska omsättningen något, men det löser inte grundproblemet: portföljen styrs fortfarande av en artificiell gräns i stället för av signalens styrka. Det introducerar även nya problem, men mer om det en annan gång.
Det finns dessutom ett statistiskt problem här.
När man omvandlar en kontinuerlig variabel till kategorier, till exempel genom att dela upp den i kvintiler eller halvor, gör man det som i statistiken kallas dikotomisering och detta innebär alltid en informationsförlust. En klassisk tumregel är att man behöver ungefär 57 % mer data för att kompensera för informationen som går förlorad när en kontinuerlig variabel delas i två grupper.
Med andra ord: man kastar bort en betydande del av signalens statistiska styrka.
Ett enkelt alternativ är en rankningsviktad portfölj, där varje akties vikt är proportionell mot dess faktorrang eller faktorscore. Då skalar vikterna kontinuerligt med signalen, omsättningen drivs av faktiska förändringar i signalen och portföljens koncentration anpassar sig naturligt efter hur stark signalen är.
Betingade sorteringar: dubbelt problematiska
En vanlig vidareutveckling är så kallade betingade sorteringar.
Ett typiskt exempel ser ut så här:
Ta topp 50 % på faktor A (till exempel kvalitet).
Rangordna de återstående aktierna på faktor B (till exempel värdering).
Bygg portföljen från den andra rangordningen.
Idén låter rimlig: filtrera först på kvalitet, välj sedan de billigaste aktierna.
Men detta skapar två problem.
Det första är samma som tidigare. Den hårda tröskeln på faktor A kastar bort information och skapar diskret omsättning runt medianen.
Det andra problemet är mer subtilt.
En betingad sortering testar egentligen inte om A och B var för sig är prediktiva. Den testar om B fungerar givet att man redan befinner sig i topphalvan av A.
I regressionstermer estimerar man alltså inte
utan snarare något som liknar
Det vill säga att en interaktion mellan A och B smygs in i modellen.
Varför spelar detta roll?
Därför att interaktionseffekter är mycket svårare att hitta statistiskt än vanliga huvudeffekter. En vanlig tumregel är att man behöver ungefär 16 gånger mer data för att kunna identifiera en interaktion med samma statistiska säkerhet som en enkel effekt.
Det betyder att en betingad sortering kan se ut att fungera även om faktor B egentligen inte har någon egen prediktiv kraft, så länge interaktionen mellan A och B råkar vara positiv. Samtidigt ignoreras all information om B i den nedre halvan av A-fördelningen.
Interaktionen finns alltså där, men den är gömd i sorteringsregeln.
Vad man kan göra i stället
Ett mer transparent sätt är att arbeta med signalerna direkt.
I stället för sortering kan man bygga ett enkelt kompositmått där man inkluderar
faktor A
faktor B
och, om det finns en ekonomisk och statistisk motivering, interaktionen A × B
Varje komponent kan då estimeras och testas separat.
Detta har flera fördelar:
hela aktieuniversumet används
kontinuerlig information bevaras
interaktioner blir explicita och testbara
Framför allt blir portföljvikterna proportionella mot signalens styrka i stället för att bestämmas av godtyckliga bucket-gränser.
Sorteringsportföljer är enkla. Men enkelheten är ofta vilseledande.
När man tar hänsyn till informationsförlusten från dikotomisering, den onödiga omsättningen och de dolda interaktionseffekterna blir det tydligt att denna metod ofta kostar mer än den smakar.